



Machine learning for genomics analysis is a field that applies artificial intelligence and computational methods to analyze and interpret large and complex genomic data sets. Genomic data sets are collections of DNA or RNA sequences that contain information about the structure and function of genes, genomes, and their interactions.
Machine learning for Genomics can help discover patterns, features, and relationships in genomic data that are otherwise difficult to detect by human experts or traditional statistical methods. Machine learning for Genomics is a branch of artificial intelligence that uses algorithms and data to learn from patterns and make predictions. Machine learning is widely used in genomics, which is the study of the complete set of genetic information of an organism.
Why is there a need for Machine Learning for genomics?
From 2021, 20 years have passed then the innovative completion of the draft human genome sequence. This innovative has led to the generation of an unexpected amount of genomic data. Guesses predict that genomics research will generate between 2 and 40 exabytes of data within the next decade.
DNA sequencing and biological techniques will continue to increase the number and complication of data. This is why genomics researchers need machine learning based computational tools that can help into handle, extract and interpret the valuable information hidden within this large number of data.
Introduction
Machine learning for Genomics is an interesting and fast growing field that applies machine learning algorithms to solve various problems in bioinformatics, such as analyse biological data, predicting gene sequences, protein structures, drugs interactions. Some tasks cannot be defined well except by example that is we might be able to specify input/output pairs but not a compact relationship between inputs and output.
We might be like machines to be able to adjust their internal structure to produce actual outputs for a large number of samples inputs and thus appropriately check their input/output function to approximate the relationship unexpressed in the examples.
Producers frequently produce machines that do not work as well as desired in the environments in which they are used. In fact, certain characteristics of the working environment might not be completely known at design time.
Machine learning for genomics is a interesting and fast growing field that applies machine learning algorithms to solve various problems in bioinformatics such as predicting gene sequencing, drug interaction, structures of protein analysis of biological data and many more biological things such as genomics, metagenomics etc.
Machine learning for genomics methods can be divided into supervised, semi-supervised and unsupervised methods. Supervised methods are trained on examples with labels and are then used to predict these labels on other examples, whereas unsupervised methods find patterns in data sets without the use of labels. Semi-supervised methods combine these two approaches, leveraging patterns in unlabelled data to improve power in the prediction of labels.
Some of the Tools used in Machine Learning for Genomics:
Artificial Intelligence, Machine Learning and Genomics: This is a fact sheet from the National Human Genome Research Institute (NHGRI) that provides an overview of the concepts and applications of artificial intelligence and machine learning in genomics, as well as the challenges and opportunities for future research.
A review of deep learning applications in human genomics using next-generation sequencing data: This is a review article that discusses how deep learning, a subfield of machine learning that uses neural networks to learn from complex and high-dimensional data, is applied in different subareas of human genomics, such as gene expression, variant calling, disease prediction, and drug discovery.
PlasClass (published 2020, PLOS)
Uses logistic regression on k-mer frequency vectors to detect whether they originate from a plasmid sequence or a chromosomal segment. This is a binary classification based tool.
PlasFlow (published 2018, Nucleic Acid Research)
This tool predicts the phylum level classification and predicts whether a given contig is a plasmid or a chromosome. Uses a neural network on top of k-mer frequency vectors.
MetaBCC-LR (published, 2020, Bioinformatics)
Uses t-distributed Stochastic Neighbour Embedding (t-SNE) to dimension reduce genomic long reads to perform binning of metagenomic reads’ trimer vectors
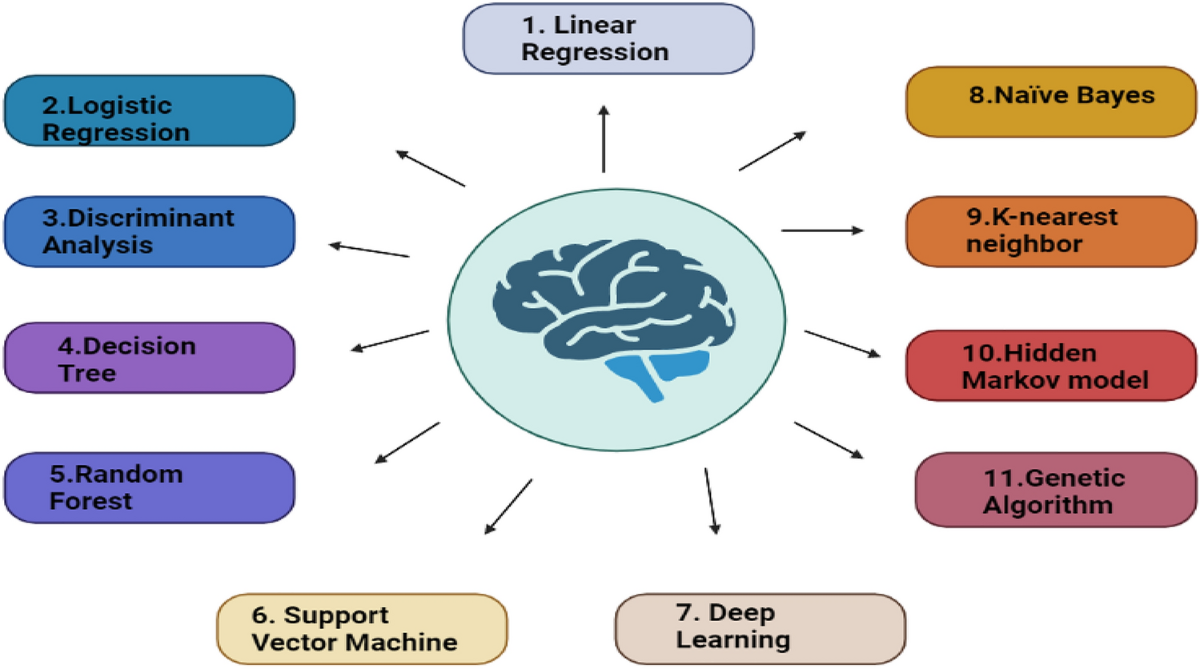
Commonly used machine learning algorithms in genomics
Some of the most widely used learning algorithms are support linear discriminant analysis, linear regression, logistic regression, naive Bayes, vector machines, decision trees, k-nearest neighbour algorithm and Neural Networks (multilayer perception)
Challenges In Applying Machine Learning for Genomics
Data quality and quantity:
Genomic data can be noisy, incomplete, imbalanced, or heterogeneous, which can affect the performance and reliability of machine learning models. For example, sequencing errors, missing values, batch effects, or different data sources can introduce biases or confounders in the data.
Moreover, genomic data can be very high-dimensional, sparse, or complex, which can pose computational and statistical challenges for machine learning algorithms. Therefore, proper data pre-processing, normalization, integration, and dimensionality reduction are essential steps before applying machine learning to genomics.
Model selection and evaluation:
Choosing the most appropriate machine learning algorithm and parameters for a given genomic task can be difficult, as different algorithms may have different assumptions, strengths, and limitations. For example, some algorithms may be more suitable for linear or non-linear problems, discrete or continuous outcomes, or classification or regression tasks.
Moreover, evaluating the performance and generalizability of machine learning models can be challenging, as genomic data can have complex and unknown structures, such as hierarchical, temporal, or spatial dependencies, that can violate the common assumptions of independent and identically distributed data.
Therefore, proper model selection, validation, and testing methods are crucial steps to ensure the robustness and accuracy of machine learning models in genomics.
Interpretability and explainability
Understanding the logic and rationale behind the predictions and decisions of machine learning models can be challenging, especially for complex and nonlinear models, such as deep neural networks. For example, it may be hard to identify which genomic features or interactions are most important or relevant for a given outcome, or how the model handles uncertainty or errors.
Moreover, explaining the results and implications of machine learning models to domain experts, such as biologists, clinicians, or policy makers, can be challenging, as they may have different levels of familiarity and expectations with machine learning methods.
Therefore, proper interpretability and explainability methods are important steps to ensure the transparency and accountability of machine learning models in genomics.
Areas of Application
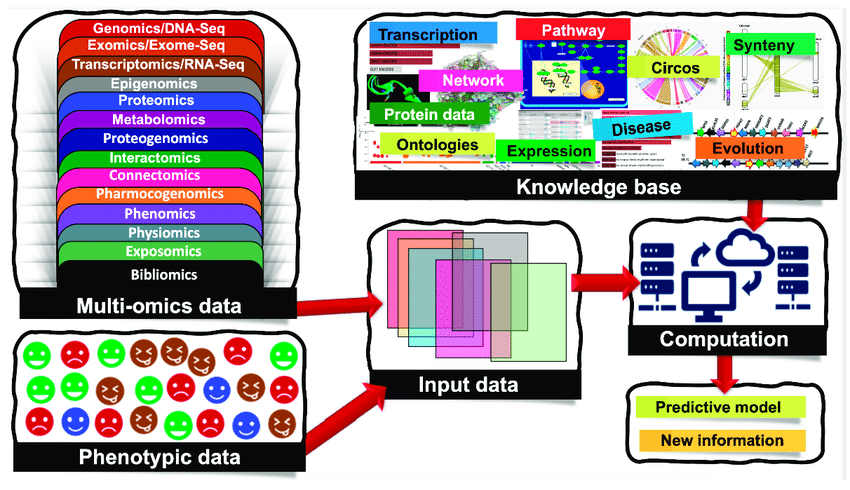
There are many circumstances in genomics that might use from machine learning. The main areas of Clustering and Classification can be used in Genomics.
Clustering (Unsupervised Learning)
- Binning of Metagenomics Contigs
- Identification of Plasmids and Chromosomes
- Clustering reads into chromosomes for assembly
- Clustering of reads as a pre-processor for assembly of reads
Classification (Supervised Learning)
- Classifying shorter sequences in to the classes
- Phylogenetic inference of the sequences
- Detection of Plasmids and Chromosomes
- Finding coding regions
- Chromosome prediction in human genomics
Machine learning for genomics is a branch of artificial intelligence that allows computers to learn from data without being explicitly programmed. Machine learning has many applications in genomics, which is the study of the complete set of genes within a particular organism.
Some of the applications are:
- Genome sequencing: Machine learning can help with analyzing and interpreting the large and complex data generated by genome sequencing technologies, such as next-generation sequencing (NGS). Machine learning can help with improving the accuracy, speed, and cost of genome sequencing, as well as identifying variants, mutations, and structural changes in the genome.
- Gene editing: Machine learning can help with designing and optimizing gene editing tools, such as CRISPR-Cas9, which can make precise and targeted changes to the DNA of living cells. Machine learning can help with predicting the outcomes, effects, and risks of gene editing, as well as finding the best targets and guides for gene editing.
- Disease diagnosis and prognosis: Machine learning can help with diagnosing and predicting diseases based on genomic data, such as DNA, RNA, or protein sequences. Machine learning can help with finding biomarkers, signatures, and patterns that are associated with diseases, as well as classifying and subtyping diseases based on genomic features.
- Drug discovery and development: Machine learning can help with discovering and developing new drugs based on genomic data, such as protein structures and functions. Machine learning can help with finding potential drug targets and candidates, as well as simulating and optimizing the interactions between drugs and proteins.
Advantages Of using Machine Learning for Genomics
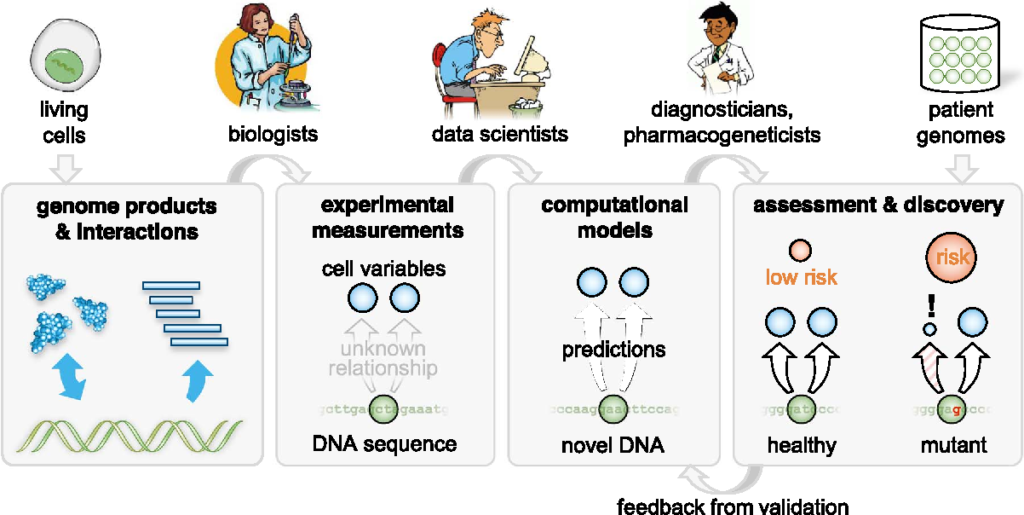
- Identifies variant across a range of applications.
- Achieves comprehensive coverage of coding regions
- Provides a cost-effective difference
- Produces a smaller, easy to manage data set for faster, data analysis easily.
- Provides a high resolution, reads of the genome
- Captures the both large and small variants that missed with targeted approaches
- Identifies potential variant for further follow up studies of the gene expression and regulating mechanisms.
- Delivers a large volume of data in a short period of time to support assembly of new genomes.
Benefits Of Using Machine Learning for Genomics
- Cost effectiveness
- Fast
- Ultra throughput (through screening )
- Cloning free
- Shorts read
If you want to know more about applications of Machine Learning the field of Bioinformatics you can join us for a 3 Hour Short Course on Machine Learning for Bioinformatics, you can register yourself HERE
You can read more about applications of Data Science in Bioinformatics HERE
This article is originally published HERE






0 Comments